Après avoir appris à créer votre premier réseau de neurones dans l’article Mon premier réseau de neurones et avoir étudié la théorie de l’optimisation d’un modèle dans l’article Optimisation simple d’un réseau de neurones, il est maintenant temps de s’exercer à entraîner efficacement un réseau de neurones ! 🚀
nnnnPour cela, nous allons reprendre ensemble la création du modèle de l’article Mon premier réseau de neurones. Nous allons effectuer plusieurs entraînements afin de déterminer l’importance du taux d’apprentissage (learning rate) dans l’entraînement d’un modèle. Si vous avez un doute sur la notion de learning rate, l’article Optimisation simple d’un réseau de neurones est là pour vous accompagner.
nnnnPréparation du Notebook
nnnnBien ! Commençons d’abord par toutes les installations et imports dont nous aurons besoin lors de ce TP. Nous utiliserons encore une fois Jupyter pour développer.
nnnnOn crée un environnement virtuel Python (inutile si vous l’avez déjà créé pour l’article Mon premier réseau de neurones) :
nnnnpython3 -m venv test_iaOn active l’environnement virtuel Python :
nnnncd test_ian. bin/activateOn installe Jupyter et on le lance :
nnnnpip install jupyternjupyter notebookLa dernière commande ouvre automatiquement Jupyter dans votre navigateur. Il vous suffit ensuite de créer un Notebook en allant dans « File » → « New » → « Notebook ». Copiez ensuite le code suivant dans le Notebook.
nnnnInstallations & Imports *1
nnnn*1 : Cette étape a également été faite dans le premier TP décrit dans l’article Mon premier réseau de neurones.
nnnnIl nous faut tout d’abord installer les bibliothèques suivantes :
nnnn- n
- Pytorch, une des principales bibliothèques Python pour faire des réseaux de neurones. Ici on n’installe que la version CPU, la version de base fonctionne avec CUDA, la bibliothèque de calcul scientifique de Nvidia, mais celle-ci prend beaucoup de place sur le disque dur, restons frugaux. nnnn
- Pandas, la bibliothèque Python star de la data-science, basée elle-même sur Numpy (pour la gestion de listes). nnnn
- Matplotlib, pour faire de jolis graphiques. n
!pip3 install torch --index-url https://download.pytorch.org/whl/cpun!pip install pandasn!pip install matplotlibUne fois les installations effectuées, on peut passer à l’importation de ces bibliothèques ou bien des éléments spécifiques de ces dernières.
nnnnimport torchnimport torch.nn.functional as Fnnimport pandas as pdnnimport matplotlib.pyplot as pltnnfrom random import randint, seedn# Nous n'avons pas eu besoin d'installer random car c'est une bibliothèque standard de PythonTout est maintenant en place pour bien débuter le TP !
nnnnCréation d’un jeu de données
nnnnLa première étape pour entraîner notre modèle est de créer un jeu de données adapté à notre problématique sur lequel nous pourrons entraîner notre modèle.
nnnnOn prend cette fois en exemple un skieur en bas d’une montagne qui remonte la pente jusqu’au sommet de cette dernière.
nnnnPar conséquent, il nous faut un jeu de données qui représente la pente de cette montagne pour entraîner notre modèle.
nnnnPour cet exemple, on prendra une pente très simple et linéaire d’équation f(x) = 2x. C’est donc cette fonction, une version simplifiée de l’article précédent, que l’on va utiliser pour créer notre jeu de données.
nnnndata = pd.DataFrame(columns=["x", "y"],n data=[(x, x*2) for x in range(10)],n )ndata["x"] = data["x"].astype(float)ndata["y"] = data["y"].astype(float)nn# On peut visualiser le jeu de données d'entraînement ci-dessousnplt.figure(figsize=(25, 5))nplt.margins(0)nplt.scatter(data["x"], data["y"], alpha=0.5)nplt.title("Jeu de données d'entraînement")nplt.xlabel("Position x")nplt.ylabel("Altitude y")nplt.grid(True)nplt.show()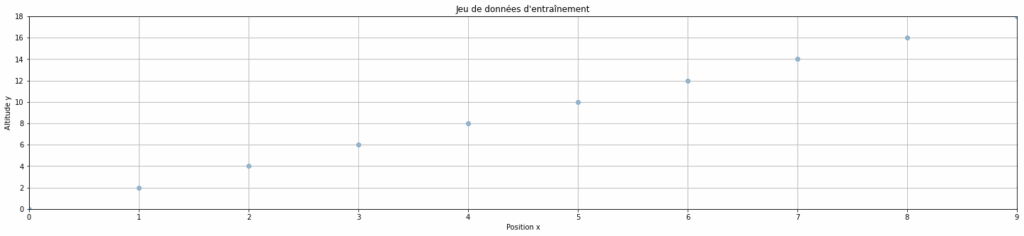
Création de notre modèle
nnnnMaintenant que notre jeu de données est prêt, on peut maintenant passer à la création de notre modèle.
nnnnOn va créer un modèle très simple car notre problématique n’est pas très complexe. En effet, la pente de notre montagne est linéaire, par conséquence, notre modèle n’a besoin que d’une couche de neurones. Pour le créer, on va utiliser PyTotch avec une seed (graine) fixe pour avoir des résultats reproductibles.
nnnntorch.manual_seed(1337)nseed(1337)nnM = torch.randn((1,1))nM.requires_grad = Truennprint(M)Entraînement de notre modèle
nnnnNotre modèle ainsi que notre jeu de données étant prêts, on peut maintenant passer à l’entraînement de ce dernier.
nnnnPour entraîner notre modèle, il nous manque encore deux variables à définir : epochs et lr.
nnnn- n
- epochs (époques) représente le nombre de fois où l’on entraîne le modèle sur un échantillon de données nnnn
- lr est l’abréviation de learning rate et représente le taux de mise à jour des poids du modèle lors de la descente de gradient (backward pass ou backward propagation) n
epochs = 700nlr = 0.1nlosses = list()nnfor epoch in range(epochs):n # On sélectionne un point de données aléatoire parmi les 10 du datasetn # Cela permet de varier les données vues à chaque epochn ix = randint(0, len(data) - 1)n x = data.iloc[ix]["x"]n y = data.iloc[ix]["y"]nn # Forward passn y_prevision = M @ torch.tensor([x]).float()nn # Calcul de la loss (perte)n loss = F.l1_loss(y_prevision, torch.Tensor([y]))nn # Backward passn M.grad = Nonen loss.backward()nn # Mise à jour du learning rate et de Mn lr = 0.1 # On conserve le même learning raten M.data += -lr * M.gradnn # stats : on stocke la loss pour suivre la progression de l'entraînementn losses.append(loss.item())Affichage et interprétation des résultats
nnnnLors de l’entraînement, nous avons stocké la loss de chaque epoch, on peut maintenant visualiser comment cette loss a évolué au fil de l’entraînement du modèle.
nnnnplt.figure(figsize=(25, 5))nplt.margins(0)nplt.plot(range(epochs), losses, linestyle='-', color='b', label="Loss")nplt.xlabel("Epochs")nplt.ylabel("Loss")nplt.title("Évolution de la loss au fil des epochs")nplt.legend()nplt.grid(True)nplt.show()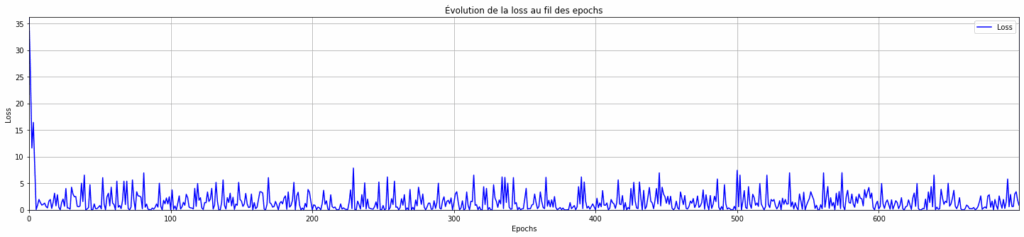
On observe que notre modèle converge très vite, mais à tout de même du mal à se stabiliser (l’ampleur des oscillations reste identique tout au long de l’entraînement).
nnnnOn peut aussi voir l’impact sur les prédictions des données. En d’autres termes, est-ce que les prédictions sont proches de la pente réelle ? Pour cela, il suffit d’appliquer notre modèle entraîné sur le jeu de données initial.
nnnnpredictions = []nfor x in data["x"]: # Pour chaque x du jeu de données originaln y_pred = (M * x).item() # On applique notre modèle entraîné : y = M * xn predictions.append((x, y_pred))nnplt.figure(figsize=(25, 5))nplt.margins(0)nplt.scatter(data["x"], data["y"], alpha=0.5, label="Données réelles")nplt.plot([x[0] for x in predictions], [y[1] for y in predictions], label="Prédictions", color='r')nplt.title("Données réelles vs Prédictions")nplt.xlabel("Position x")nplt.ylabel("Altitude y")nplt.grid(True)nplt.legend()nplt.show()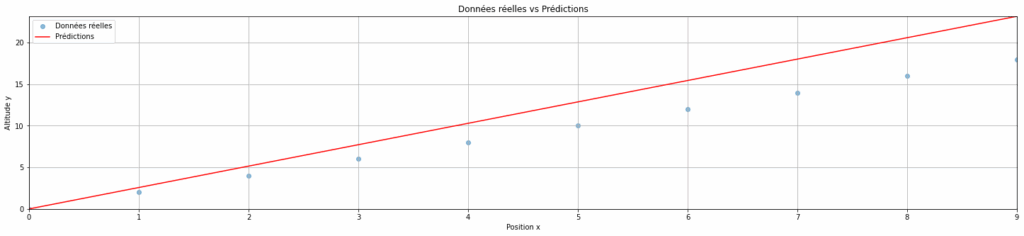
On peut voir que notre modèle fait des prédictions assez proches des données réelles, mais qu’elles ne sont pas tout à fait exactes. Voyons si nous pouvons améliorer notre entraînement.
nnnnEntraînement alternatif du modèle
nnnnAfin d’améliorer les prédictions de notre modèle, on peut essayer de jouer sur le learning rate.
nnnnPour notre premier test, on a utilisé un learning rate élevé (0,1), ce qui signifie qu’à chaque itération, les paramètres (poids et biais) du modèle sont grandement ajustés (ce qui explique les oscillations sur la loss).
nnnnOn va donc maintenant tenter le même entraînement, mais avec un learning rate faible (0,001).
nnnntorch.manual_seed(1337)nseed(1337)nM = torch.randn((1,1))nM.requires_grad = Truenprint(M)nnepochs = 700 # On conserve le même nombre d'epochs que pour le modèle précédentnlr = 0.001 # On choisit un learning rate plus faible pour voir son impact sur la convergence du modèlenlosses = list()nnfor epoch in range(epochs):n # Échantillon aléatoiren ix = randint(0, len(data) - 1)n x = data.iloc[ix]["x"]n y = data.iloc[ix]["y"]nn # Forward passn y_prevision = M @ torch.tensor([x]).float()nn # Calcul de la lossn loss = F.l1_loss(y_prevision, torch.Tensor([y]))nn # Backward passn M.grad = Nonen loss.backward()nn # Mise à journ lr = 0.001 # On conserve le learning rate faiblen M.data += -lr * M.gradnn # statsn losses.append(loss.item())nn# Prédictions finales pour les comparer avec les données réelles plus tardnpredictions = []nfor x in data["x"]:n y_pred = (M * x).item()n predictions.append((x, y_pred))nn# Visualisation de la loss en fonction des epochsnplt.figure(figsize=(25, 5))nplt.margins(0)nplt.plot(range(epochs), losses, linestyle='-', color='b', label="Loss")nplt.xlabel("Epochs")nplt.ylabel("Loss")nplt.title("Évolution de la loss au fil des epochs")nplt.legend()nplt.grid(True)nplt.show()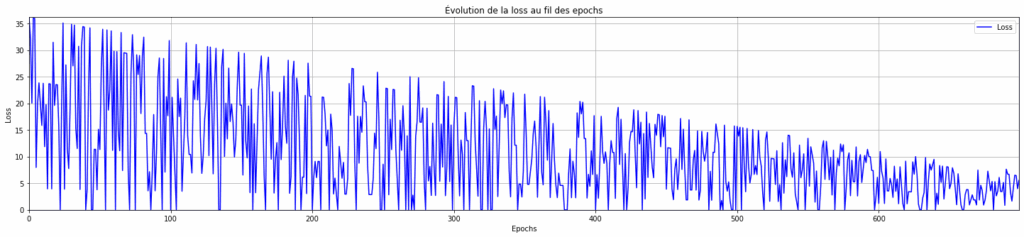
On peut observer qu’avec un learning rate faible, le modèle ne converge pas en 700 epochs (on a toujours une pente descendante et pas de plateau).
nnnnUn learning rate faible signifie qu’à chaque itération, les paramètres (poids et biais) du modèle sont très peu modifiés. On essaye de faire des petits ajustements sur ces derniers pour converger avec le moins d’oscillations possibles à la fin de l’entrainement.
nnnnDonc, pour converger avec un learning faible, il nous faut un nombre supérieur d’epochs, simplement pour laisser le temps au modèle de converger. Par conséquent, on va retenter l’entraînement précédent, mais cette fois, avec 1000 epochs.
nnnntorch.manual_seed(1337)nseed(1337)nM = torch.randn((1,1))nM.requires_grad = Truenprint(M)nnepochs = 1000 # On augmente le nombre d'epochs pour voir si le modèle fini par converger avec un learning rate faiblenlr = 0.001 # On conserve le learning rate faiblenlosses = list()nnfor epoch in range(epochs):n # Échantillon aléatoiren ix = randint(0, len(data) - 1)n x = data.iloc[ix]["x"]n y = data.iloc[ix]["y"]nn # Forward passn y_prevision = M @ torch.tensor([x]).float()nn # Calcul de la lossn loss = F.l1_loss(y_prevision, torch.Tensor([y]))nn # Backward passn M.grad = Nonen loss.backward()nn # Mise à journ lr = 0.001n M.data += -lr * M.gradnn # statsn losses.append(loss.item())nn# Prédictions finales pour les comparer avec les données réelles plus tardnpredictions = []nfor x in data["x"]:n y_pred = (M * x).item()n predictions.append((x, y_pred))nn# Visualisation de la loss en fonction des epochsnplt.figure(figsize=(25, 5))nplt.margins(0)nplt.plot(range(epochs), losses, linestyle='-', color='b', label="Loss")nplt.xlabel("Epochs")nplt.ylabel("Loss")nplt.title("Évolution de la loss au fil des epochs")nplt.legend()nplt.grid(True)nplt.show()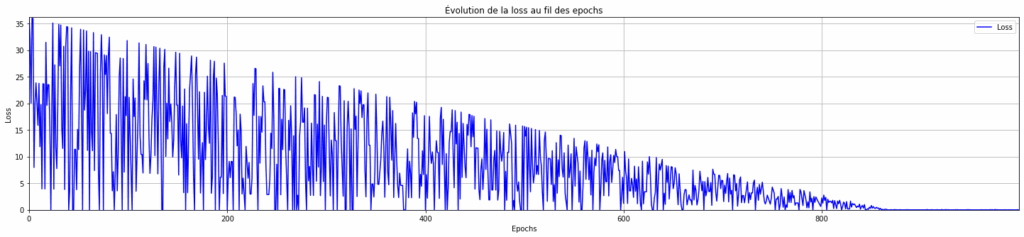
Là, on peut voir qu’avec un learning rate faible (0,001) mais un grand nombre d’epochs (1000), le modèle fini bien par converger.
nnnnMais, est-ce que les prédictions du modèle sont plus justes ? C’est ce que l’on va voir juste après.
nnnnplt.figure(figsize=(25, 5))nplt.margins(0)nplt.scatter(data["x"], data["y"], alpha=0.5, label="Données réelles")nplt.plot([x[0] for x in predictions], [y[1] for y in predictions], label="Prédictions", color='r')nplt.title("Données réelles vs Prédictions")nplt.xlabel("Position x")nplt.ylabel("Altitude y")nplt.grid(True)nplt.legend()nplt.show()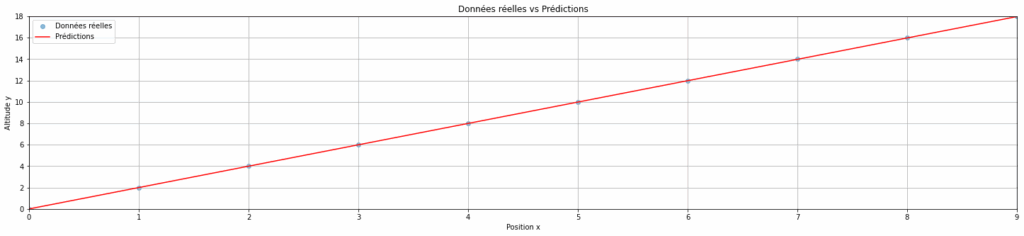
Comme on peut le voir sur le graphique ci-dessus, les prédictions du modèle sont bien meilleures avec un faible learning rate ! 🎉
nnnnEntraînement optimale du modèle
nnnnComme vu précédemment, les entraînements avec un learning rate élevé et un learning rate faible ont tous deux leurs avantages et inconvénients.
nnnnD’un côté, un learning rate élevé permet au modèle de converger très vite, mais avec de grandes oscillations, ce qui peut, parfois, dire que la loss ne se stabilise jamais et donc le modèle peut faire de mauvaises prédictions. De l’autre côté un learning rate bas permet d’avoir à coup sûr une loss stable à la fin de l’entraînement, mais avec un grand nombre d’epochs, donc un entraînement plus long et un plus grand coût de calculs.
nnnnPour avoir le meilleur des deux mondes, on va tester d’entraîner notre modèle avec un learning rate adaptatif : élevé initialement pour converger rapidement, puis faible pour stabiliser la loss.
nnnntorch.manual_seed(1337)nseed(1337)nM = torch.randn((1,1))nM.requires_grad = Truenprint(M)nnepochs = 150 # On repasse à un nombre d'epochs faiblenlr_initial = 0.1 # On commence à un learning rate élevé pour converger rapidementnlr_final = 0.001 # On fini à un learning rate faible pour stabiliser la lossnlosses = list()nnfor epoch in range(epochs):n # Échantillon aléatoiren ix = randint(0, len(data) - 1)n x = data.iloc[ix]["x"]n y = data.iloc[ix]["y"]nn # Forward passn y_prevision = M @ torch.tensor([x]).float()nn # Calcul de la lossn loss = F.l1_loss(y_prevision, torch.Tensor([y]))nn # Backward passn M.grad = Nonen loss.backward()nn # Mise à journ if epoch < 50:n lr = lr_initial # Pour les 50 premières epochs, on conserve le learning rate initial (élevé : 0,1)n else:n lr = lr_final # Passé la barre des 50 premières epochs, on passe à au learning rate final (faible : 0,001)nn M.data += -lr * M.gradnn # statsn losses.append(loss.item())nn# Visualisation de la loss en fonction des epochsnplt.figure(figsize=(25, 5))nplt.margins(0)nplt.plot(range(epochs), losses, linestyle='-', color='b', label="Loss")nplt.xlabel("Epochs")nplt.ylabel("Loss")nplt.title("Évolution de la loss au fil des epochs")nplt.legend()nplt.grid(True)nplt.show()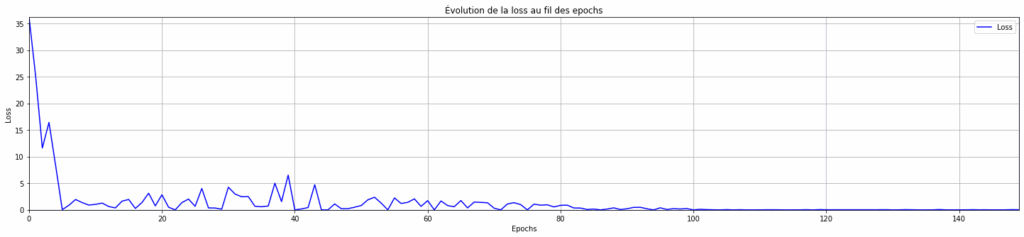
On observe qu’avec un learning rate adaptatif, le modèle converge très bien et la loss se stabilise en un nombre d’epochs très faible !
nnnnDonc le learning rate adaptatif est une meilleure solution (en efficacité et performance) pour entraîner un modèle. Le coût d’entraînement est plus faible et le modèle fait de meilleures prédictions.
nnnnCette fonction d’adaptation est en fait appelée un scheduler et elle sert à ajuster dynamiquement un hyperparamètre de l’entraînement. Dans notre cas l’hyperparamètre est le learning rate donc on parle plus précisément de lr scheduler.
nnnnPour notre lr scheduler, nous avons fait une fonction très simple. En effet, on part avec un learning rate élevé, puis, passé 50 epochs, on passe à un learning rate faible.
nnnnCependant, on pourrait également améliorer cette fonction en adaptant notre learning rate en fonction de la dernière loss calculée (et non l’epoch qui est une variable un peu naïve) : tant que la loss diminue on conserve le learning rate actuel, sinon, on le divise par deux. N’hésitez pas à tester cette version de votre côté si cela vous dit !
nnnnConclusion
nnnnPour conclure, dans ce TP, nous avons exploré les notions de learning rate et de scheduler, aspects fondamentaux de l’entraînement d’un réseau de neurones.
nnnnGrâce à différents entraînements, nous avons observé que :
nnnn✅ La backward pass permet d’ajuster les paramètres d’un modèle en minimisant une fonction de loss.
nnnn✅ Le choix du learning rate est crucial : trop élevé, la loss est instable ; trop faible, elle devient trop lente.
nnnn✅ Un learning rate adaptatif permet d’accélérer la convergence au début et de stabiliser l’apprentissage ensuite.
nnnn✅ Il existe plusieurs façons d’adapter le learning rate et les fonctions d’adaptation de ce dernier sont appelées des schedulers.
nnnnN’hésitez pas à prendre en main ce TP de votre côté pour bien maîtriser la création et l’entraînement d’un réseau de neurones. Vous pouvez par exemple tester différents learning rate ou lr schedulers pour l’entraînement de votre modèle ! 🚀
nnnnnnnn
Auteur : Mathilde POMMIER, Neogeo
nnnnn